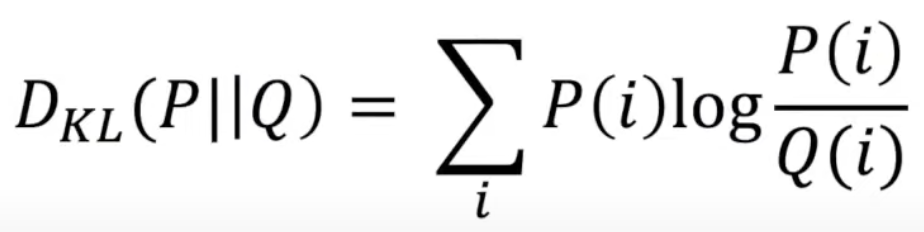L1范数和L2范数
L1范数和L2范数是在机器学习、统计学和计算数学中常用的两种向量范数,它们在优化问题、特别是在正则化过程中扮演着重要角色。
L1范数(曼哈顿距离)
L1范数,也被称为曼哈顿距离或者一范数,是向量元素绝对值的和。对于一个向量 x=[x1,x2,…,xn]\mathbf{x} = [x_1, x_2, \dots, x_n]x=[x1,x2,…,xn],其L1范数定义为:
∥x∥1=∑i=1n∣xi∣|\mathbf{x}|1 = \sum{i=1}^n |x_i|∥x∥1=i=1∑n∣xi∣
L1范数在统计学中常用于创建稀疏参数;例如,在Lasso回归中,通过L1正则化可以推动模型将某些回归系数精确地推到0,这样做有助于特征选择,从而生成一个简单且解释性强的模型。
L2范数(欧几里得距离)
L2范数,也称为欧几里得距离或者二范数,是向量元素的平方和的平方根。对于向量 x=[x1,x2,…,xn]\mathbf{x} = [x_1, x_2, \dots, x_n]x=[x1,x2,…,xn],其L2范数定义为:
∥x∥2=∑i=1nxi2\|\mathbf{x}\|_2 = \sqrt{\sum_{i=1}^n x_i^2}∥x∥2=i=1∑nxi2
L2范数在机器学习中常用于岭回归(Ridge Regression),通过L2正则化可以减小回归系数的大小,限制模型复杂度,从而避免过拟合。它也有助于处理数学上的条件数问题和数值不稳定性。
区别与应用
稀疏性:L1范数因为其线性特性,倾向于产生稀疏的系数,即很多系数为0,适合进行特征选择。而L2范数通常不会产生稀疏系数,但可以防止模型中的任何一个系
均值、方差
总体方差和样本方差是统计学中用于衡量数据分散程度的两个重要概念。它们的主要区别在于应用场景和计算方式。
1. 总体方差 (Population Variance, (\sigma^2))
定义: 总体方差是指整个数据集合(即总体)中所有数据点与总体均值之间的平方差的平均值。它用于描述整个群体(或总体)中数据的分布情况。
计算公式: 对于一个总体中的 (N) 个数据点 ({x_1, x_2, ..., x_N}),总体方差的公式是: $$ [ \sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2 ] $$
$$ \sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2 $$
其中:
- (N) 是总体中数据点的数量。
- (\mu) 是总体的均值。
- ((x_i - \mu)^2) 是每个数据点与均值之间的平方差。
使用场景: 总体方差一般在你有整个群体的数据时使用,例如,当你研究一个固定且完全已知的数据集(比如全体员工的工资数据)。
2. 样本方差 (Sample Variance, (s^2))
定义: 样本方差是从总体中随机抽取的一个样本数据集合的方差估计。由于样本方差是基于部分数据的统计量,它通常用于估计总体方差。
计算公式: 对于一个样本中的 (n) 个数据点 ({x_1, x_2, ..., x_n}),样本方差的公式是:
[ s^2 = \frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2 ]
其中:
- (n) 是样本中数据点的数量。
- (\bar{x}) 是样本的均值。
- (n-1) 称为自由度 (Degrees of Freedom),用于修正样本方差以更好地估计总体方差。
使用场景: 样本方差用于从样本数据中推断总体的特征。例如,当你只掌握了部分员工的工资数据,并想推断整个公司员工的工资分布时。
3. 为什么样本方差用 (n-1) 而不是 (n)
偏差修正: 样本方差公式中的 (n-1) 是对样本数据的修正。因为样本均值 (\bar{x}) 是从样本数据中计算出来的,而不是已知的总体均值 (\mu),使用 (n-1) 能够使样本方差成为总体方差的无偏估计量。具体来说:
- 无偏估计: 样本均值 (\bar{x}) 通常比总体均值 (\mu) 更接近样本数据,这会导致平方差 ((x_i - \bar{x})^2) 变小。因此,为了抵消这种偏差,使用 (n-1) 而不是 (n),使得方差的估计值不会系统性地低估总体方差。
4. 总结
- 总体方差 描述的是整个数据群体的分散程度,通常在你有所有数据时使用。
- 样本方差 是从样本数据估计总体方差,并通过使用 (n-1) 来修正估计偏差。
- 在实际应用中,如果你在研究一个完整的总体数据集,使用总体方差公式;如果你仅有部分数据且希望推断总体特征,使用样本方差公式。
交叉熵损失
https://colah.github.io/posts/2015-09-Visual-Information/
什么是交叉熵损失?
交叉熵损失(Cross-Entropy Loss)是机器学习和深度学习中常用的一种损失函数,特别适合用于分类任务。它主要用来衡量预测的概率分布和真实的类别分布之间的差异。
简单来说,交叉熵损失可以看作是对“错误”的惩罚程度。预测得越不准确,损失就越大。
交叉熵损失是如何计算的?
假设我们有一个样本,它的真实标签是 y_true,预测的概率分布是 y_pred。交叉熵损失的计算公式是:
CrossEntropyLoss=−∑ytrue⋅log(ypred)\text{CrossEntropyLoss} = -\sum y_{\text{true}} \cdot \log(y_{\text{pred}})CrossEntropyLoss=−∑ytrue⋅log(ypred)
在分类任务中,y_true 通常是一个“one-hot”向量,这意味着它只有一个元素为 1(表示正确类别),其余的为 0。
举个例子,如果 y_true 是 [0, 1, 0](表示类别2是正确的),而模型预测的概率是 [0.1, 0.7, 0.2],那么交叉熵损失就是:
CrossEntropyLoss=−(0⋅log(0.1)+1⋅log(0.7)+0⋅log(0.2))=−log(0.7)\text{CrossEntropyLoss} = - (0 \cdot \log(0.1) + 1 \cdot \log(0.7) + 0 \cdot \log(0.2)) = -\log(0.7)CrossEntropyLoss=−(0⋅log(0.1)+1⋅log(0.7)+0⋅log(0.2))=−log(0.7)
https://jalammar.github.io/illustrated-transformer/
KL散度